|
MercuryDPM
Beta
|
|
MercuryDPM
Beta
|
Having explained in the previous section the how to run a Mercury driver code, we next explain the form of the data output, and describe how relevant information may be extracted from this data. Mercury produces data regarding a wide range of system parameters and, as such, there exist a variety of manners in which this data may be obtained and processed.
Running a Mercury executable produces three main output files in which we are interested. Each of the files produced will carry the name of the code used followed by one of the extensions ‘.data’, ‘.fstat’ and ‘.ene’.
For instance, building and running a file named ‘example.cpp’ will produce ‘example.data’, ‘example.fstat’ and ‘example.ene’ (in addition to several other files which will be discussed in later sections [CHECK THIS IS TRUE!]).
The simplest of the three file types is the ‘.ene’ file, which allows us to interpret the time evolution of the various forms of energy possessed by the system. Data is written at predefined time steps, with the system’s total gravitational (’ene_gra’) and elastic (’ene_ela’) potential energies and translational (’ene_kin’) and rotational (’ene_rot’) kinetic energies being shown alongside the system’s centre of mass position in the x, y and z directions (’X_COM’, ’Y_COM’ and ’Z_COM’, respectively).
At each time step, the data is output as follows:
time ene_gra ene_kin ene_rot ene_ela X_COM Y_COM Z_COM
The next file type we will discuss — .data — although slightly more complicated, is perhaps the most useful and versatile of the three, as it provides full information regarding the positions and velocities of all particles within the system at each given time step.
The files are formatted as follows: at each time step, a single line stating the number of particles in the system (N), the time corresponding to the current step (time) and the maximal and minimal spatial boundaries defining the computational volume used in the simulations (xmin, ymin, zmin, xmax, ymax, zmax) is first output. This first line is structured as below:
N, time, xmin, ymin, zmin, xmax, ymax, zmax
This output is then followed by a series of N subsequent lines, each providing information for one of the N particles within the system at the current point in time. For each particle, we are given information regarding its current position in three dimensions (x, y, z), the magnitudes of the three components of its instantaneous velocity (vx, vy, vz), the radius of the particle (rad), its angular position in three dimensions (qx, qy, qz) and the three components of its instantaneous angular velocity (omex, omey, omez). The term xi represents an additional variable which can be specified by the user as described in section ??? [DO THIS!]. By default, xi represents the species index, which stores information regarding the particle’s material properties.
These parameters are output in the following order:
x, y, z, vx, vy, vz, rad, qx, qy, qz, omex, omey, omez, xi
The sequence of output lines described above is then repeated for each time step.
It should be noted that the above is the standard output required for three-dimensional data; for two-dimensional data, only five items of information are given in the initial line of each time step:
N, time, xmin, zmin, xmax, zmax
and eight in the subsequent N lines:
x, z, vx, vz, rad, qz, omez, xi
Finally, we discuss the .fstat file, which is predominantly used to calculate stresses.
The .fstat output files follow a similar structure to the .data files; for each time step, three lines are initially output, each preceded by a ‘hash’ symbol (#). These lines are designated as follows:
# time, info # info # info
where time is the current time step, and the values provided in the spaces denoted ‘info’ ensure backward compatibility with earlier versions of Mercury.
This initial information is followed by a series of Nc lines corresponding to each of the Nc particle contacts (as opposed to particles) within the system at the current instant in time.
Each of these lines is structured as follows:
time, i, j, x, y, z, delta, deltat, fn, ft, nx, ny, nz, tx, ty, tz
Here, i indicates the number used to identify a given particle and j similarly identifies its contact partner. The symbols x, y and z provide the spatial position of the point of contact between the two particles i and j, while delta represents the overlap between the two and deltat the length of the tangential spring (see section ??? [REFER TO CORRECT SECTION WHEN WRITTEN]). The parameters fn and ft represent, respectively, the absolute normal and tangential forces acting on the particles, with the relevant direction provided by the unit vectors defined by nx, ny, nz for the normal component and tx, ty, tz for the tangential component.
We begin by discussing the manner in which Mercury data can simply be ‘visualised’ - i.e. a direct, visual representation of the motion of all particles within the system produced.
ParaView may be downloaded from ??? [FIND WEBSITE] and installed by following the relevant instructions for your operating system.
Data may be visualised using the ‘data2pvd' tool, which converts the ‘.data' files output by Mercury into a Paraview file (.pvd) and several VTK (.vtu) files.
We will now work through an example, using data2pvd to visualise a simple data set produced using the example code chute_demo . From your build directory, go to the ChuteDemos directory:
and run the chute_demo code:
Note: if the code does not run, it may be necessary to first build the code by typing:
Once the code has run, you will have a series of files; for now, however, we are only interested in the '.data' files.
Since data2pvd creates numerous files, it is advisable to output these to a different directory. First, we will create a directory called chute_pvd:
We will then tell data2pvd to create the files in the directory:
In the above, the first of the three terms should give the path to the directory in which the data2pvd program is found (for a standard installation of Mercury, the path will be exactly as given above); the second is the name of the data file (in the current directory) which you want to visualise; the third gives the name of the directory into which the new files will be output (‘chute_pvd’) and the name of the files to be created ('chute').
Once the files have been successfully created, we now start ParaView by simply typing:
Which should load a screen similar to the one provided below:
Note: for Mac users, ParaView can be opened by clicking 'Go', selecting 'Applications' and opening the file manually.
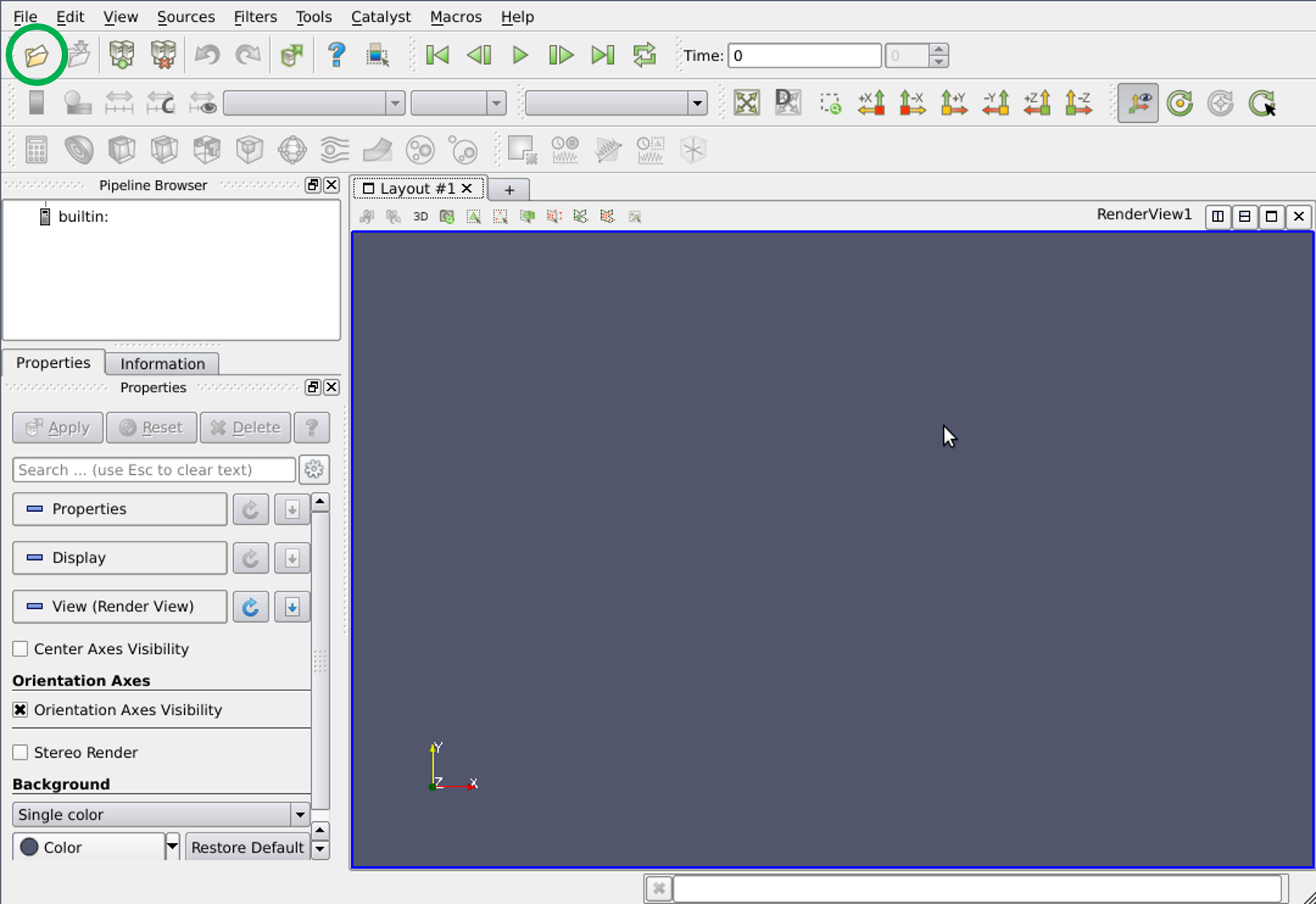
The next step is to open the file by pressing the folder icon circled in the above image and navigating to the relevant directory using the panel shown below.
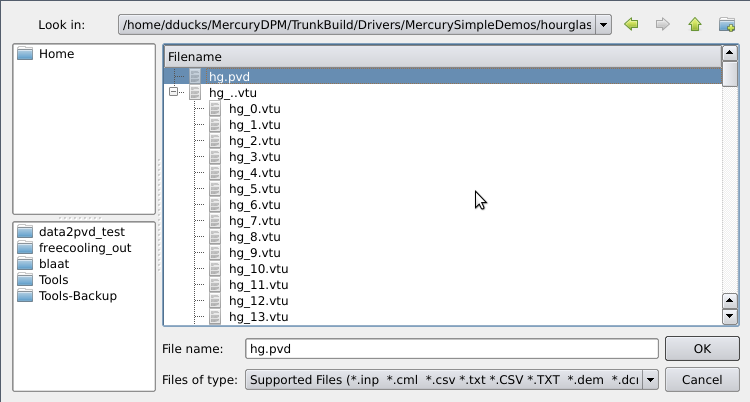
Here, you can choose to open either the `.pvd' file, which loads the entire simulation, or the '.vtu' file, which allows the selection of a single timestep.
For this tutorial, we will select the full file - ’chute.pvd'.
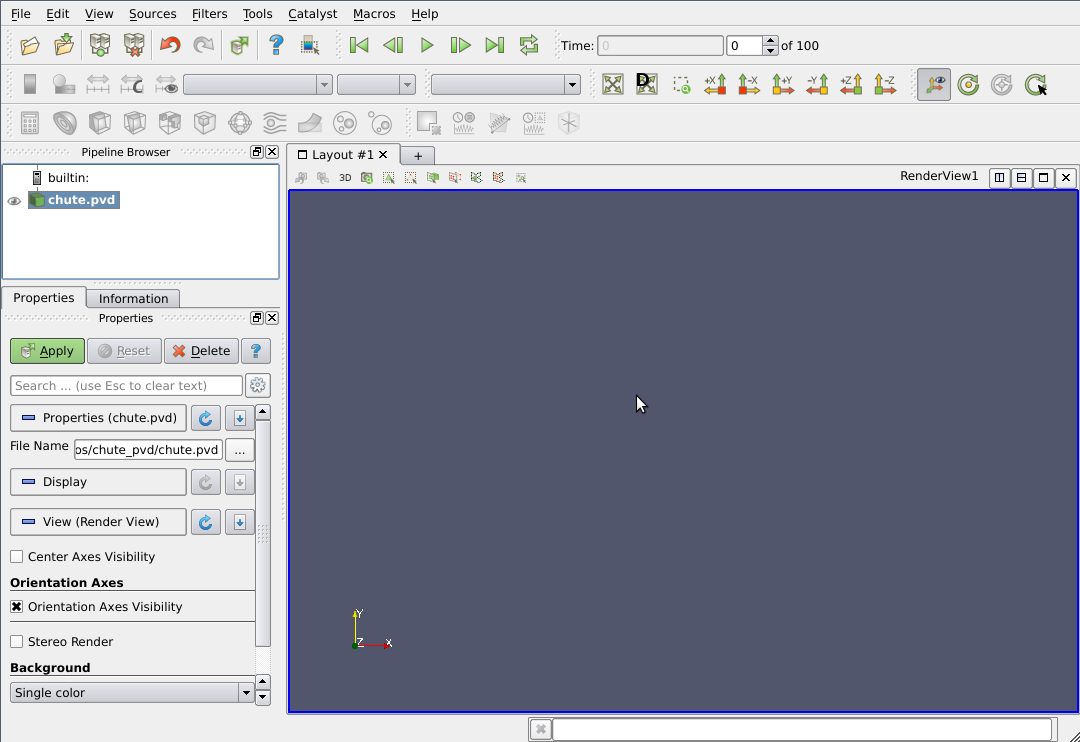
On the left side of the ParaView window, we can now see chute.pvd, below the builtin in the Pipeline Browser.
Click ‘Apply' to load the file into the pipeline.
Now we want to actually draw our particles. To do so, open the 'filters' menu at the top of the ParaView window (or, for Mac users, at the top of the screen) and then, from the drop-down list, select the 'common' menu and click 'Glyph'.
In the current case, we want to draw all our particles, with the correct size and shape. In the left-hand menu, select 'Sphere' for the ‘Glyph Type’, 'scalar' as the Scale Mode (under the ‘Scaling’ heading) and enter a Scale Factor of 2.0 (Mercury uses radii, while ParaView uses diameters).
Select 'All Points' for the ‘Glyph Mode’ under the ‘Masking’ heading to make sure all of our particles are actually rendered. Finally press 'Apply' once again to apply the changes.
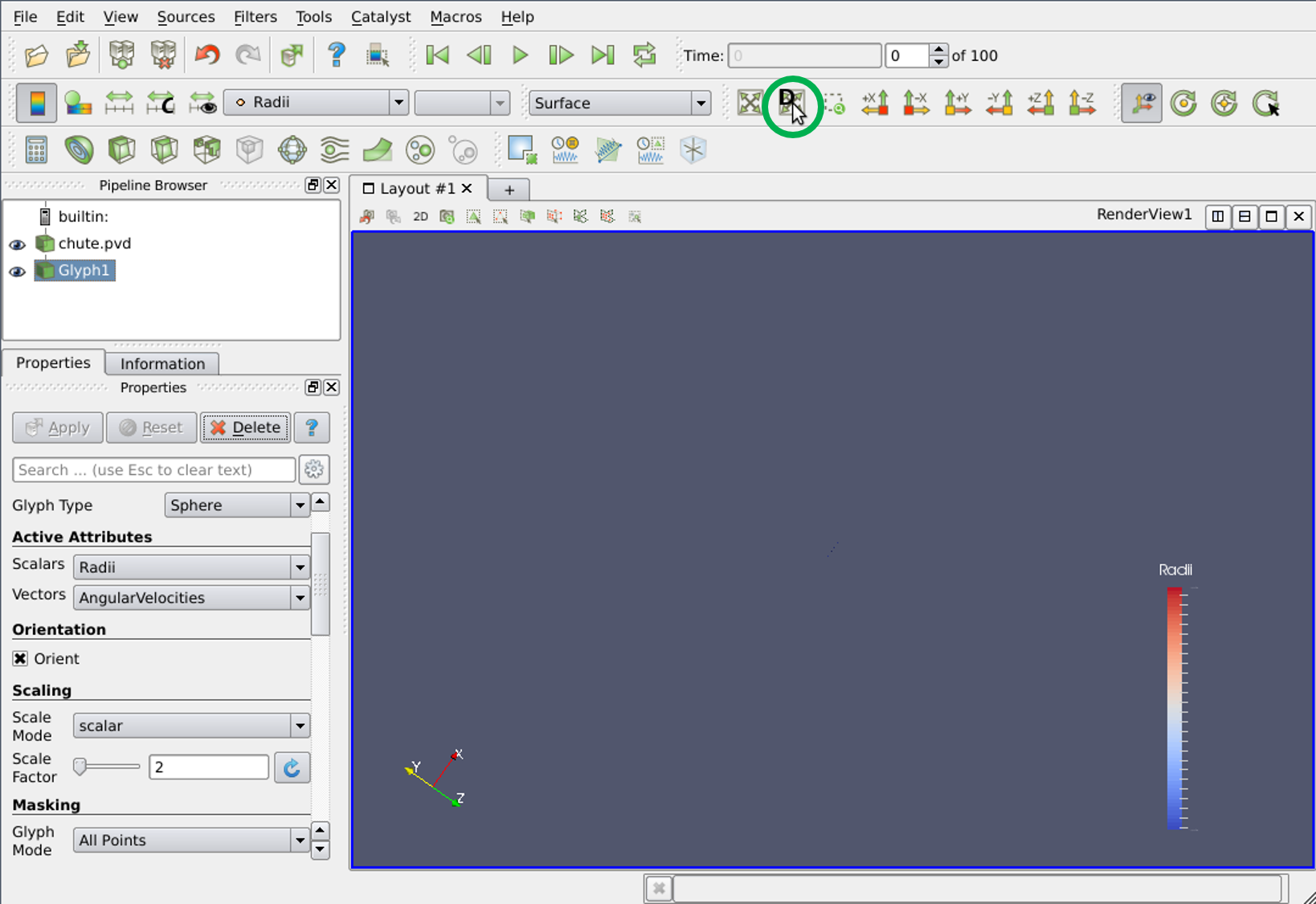
In order to focus on our system of particles, click the 'Zoom to data' button circled in the image above.
The particles can then be coloured according to various properties; for the current tutorial, we will colour our particles according to their velocities. To do this, with the 'Glyph1' stage selected, scroll down in the properties menu until you find 'Colouring' and select the 'Velocities' option.
The colouring can be rescaled for optimal clarity by pressing the ‘Rescale' button in the left hand menu under the ‘Colouring’ heading.
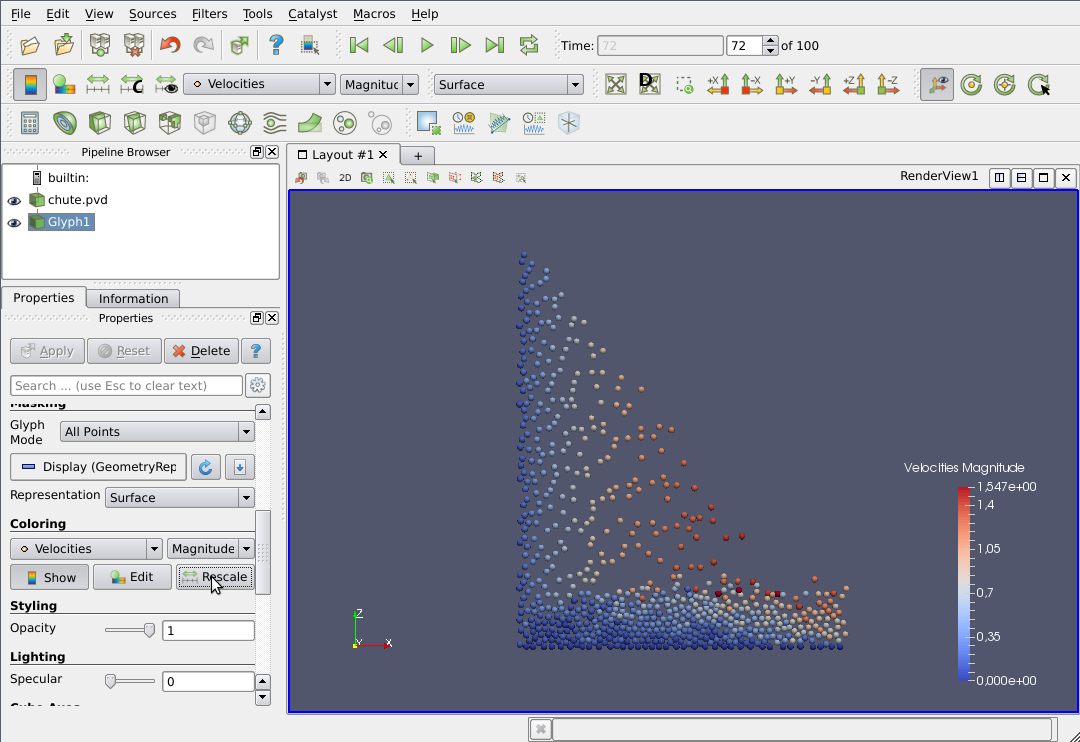
We are now ready to press the 'play' button near the top of the screen and see the system in motion!
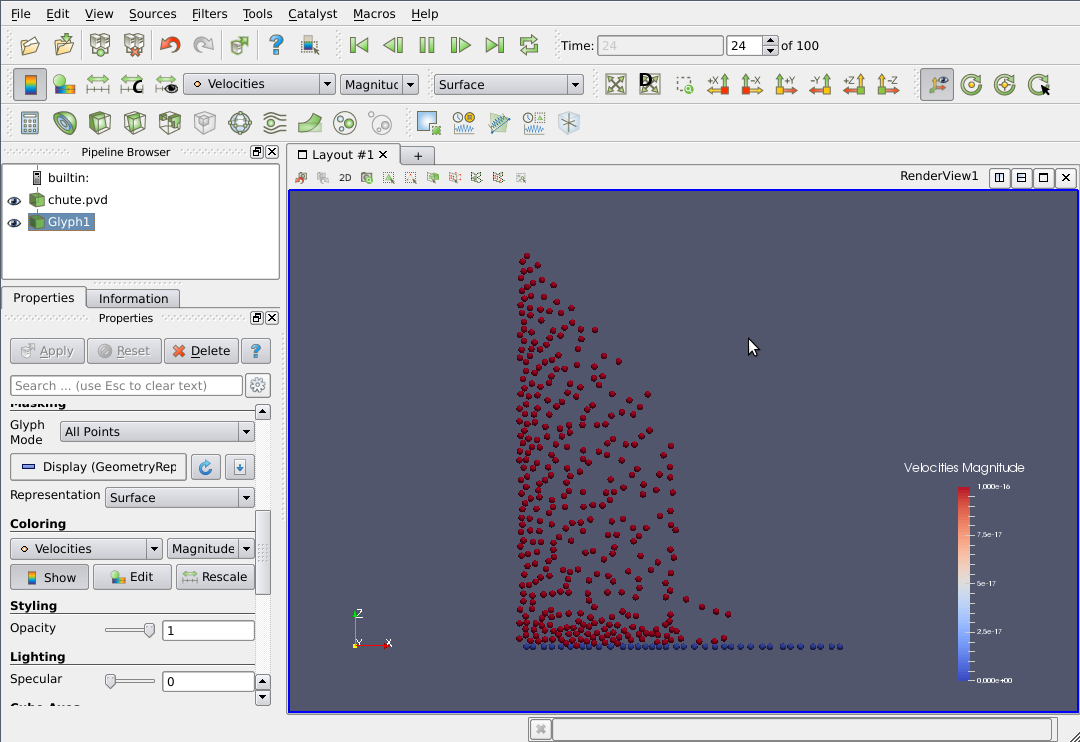
The ParaView program has endless possibilities and goes way beyond the scope of this document. Please consult the ParaView documentation for further information.
In the MercuryCG folder (MercuryDPM/MercuryBuild/Drivers/MercuryCG), type ‘make fstatistics’ to compile the ‘fstatistics’ analysis package.
For information on how to operate fstatistics, type ‘./fstatistics -help’.
The Mercury analysis package are due to be upgraded in the upcoming Version 1.1, at which point full online documentation and usage instructions will be uploaded.
If you experience problems in the meantime, please do not hesitate to contact a member of the Mercury team.
 1.8.7
1.8.7 
