|
|
|
|
By default, MercuryDPM applications running in serial produce four main output files, in ASCII format. Each of the files carries the name of the code, followed by an extension, .restart, .data, .fstat and .ene. By including the command "problem.setFileType(FileType::ONE_FILE)" in the main method below, we explicitly tell the DPM solver to write these default files:
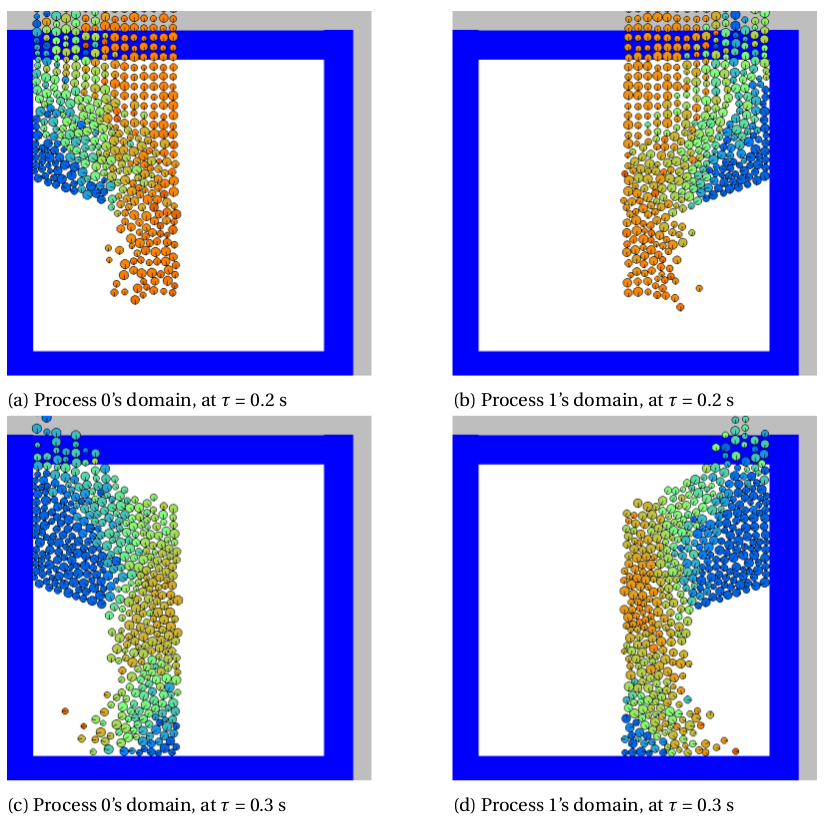
Once the previously shown spatial decomposition commands are included in the driver program, and the application is run in parallel using MPI, each process will write its own separate set of output files (.restart.n, .data.n, .fstat.n and .ene.n, n being the processor id). This is the so-called one file-per-process I/O model. In the figure below, we plot the .data.n output files for the abovementioned hourglass simulation simulated using MPI on 4 cores. We see separated parts of the entire hourglass simulation, since the .data.n files are written individually. This method requires no message-passing communications, and as a result it's quick. However, it can result into a large number of output files as the number of process/CPUs increases, that might be hard to manage and process.
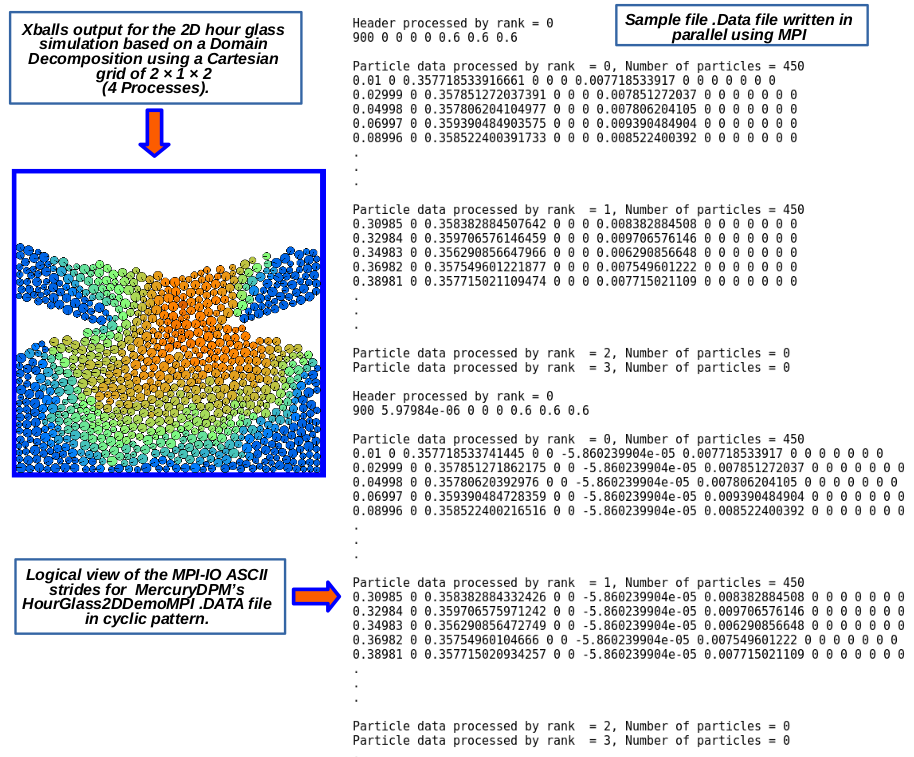
Due to the above noted issues associated with the one file-per-process model, it can be desirable to output the data to a common file, written by all processes while running the parallelised code. To do this, we set the file type to either MPI_SHARED_FILE_ASCII or MPI_SHARED_FILE_BINARY, for ASCII and binary formats respectively:
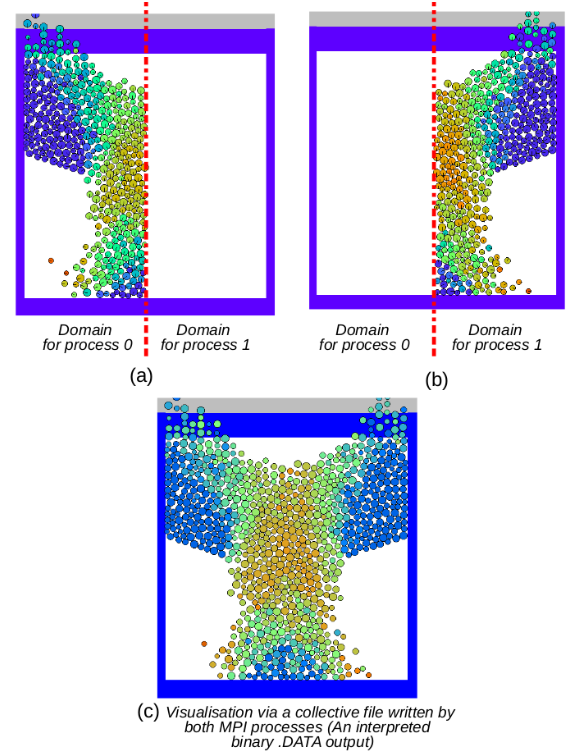
For the shared-file model, all processes open a common file and read or write different parts of the same file simultaneously. As demostrated in the Figure below, the shared-file approach maintains a single output file.
The figure below visualizes the content of the .data.n files obtained from writing one-file-per-process (subplots a and b), and the content of the .data file obtained from writing a shared file (subplot c).
Generally, in order to restart a simulation in MercuryDPM, we replace the simple solve command in the main function by solve(argc, argv), for reading in command-line arguments. Running the code with the command-line argument "-r" forces a restart; "-t [time]" can be used to reset the final time. When the MPI shared I/O model is enabled, the pallelised code is executed with the "mpirun" command as illustrated below:
When restarting the application, all processes in a parallel job will read the entire contents of the common, single restart file. For now, the parallel data readers are not smart enough to read-in only the portion of the data that they need. However, the collection of "actual data or information" that all processes require is accessible and simulations restart smoothly. Below are snapshot visualisations demonstrating the MPI-IO shared restart/read in action.
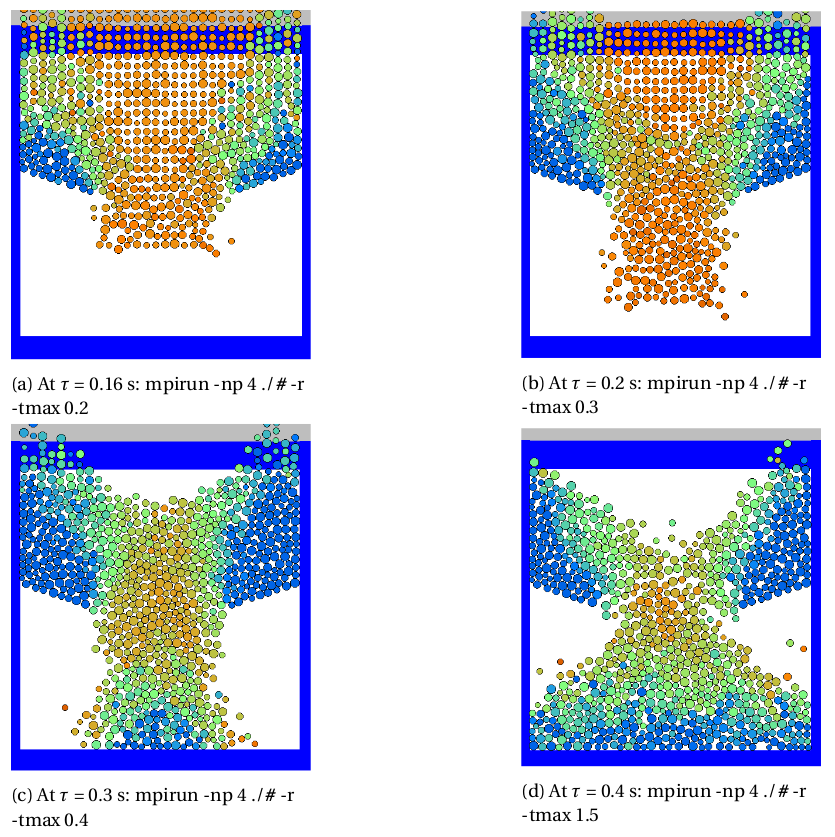
HourGlass2DDemoMPI).Finally, some performance results for comparing the above parallel I/O models are provided in the table below:

On the following pages, you'll find more parallelisation demonstrations:
Parallel processing using OpenMP
Parallel processing using MPI
Alternatively, go back to Overview of advanced tutorials