|
|
|
|
On both symmetric multiprocessors (SMPs) and massively parallel processors (MPPs), MercuryDPM can run simulations in parallel. The distinction between the computer architectures is that SMPs (single-processor machines) use shared memory, while MPPs (clusters) use distributed memory. We parallelise on shared memory with an OpenMP implementation and parallelize on distributed memory with an MPI implementation. The following tutorials will demonstrate how to use OpenMP parallelisation in your code.
To use the MercuryDPM-OpenMP framework, you need to include some code fragments in the main function, and some extra options during compiling and linking.
To illustrate this, let us consider a "Demo" application that we want to run in parallel using an activated OpenMP environment. The driver code is structured as follows:
Firstly, the OpenMP parallel environment has to be activated using cmake, i.e., by turning the flag MercuryDPM_USE_OpenMP to ON as follows:
Alternatively, you can use ccmake or cmake-gui to change the CMake configuration. Instructions for ccmake:
Next, we set the number of threads to run in parallel for the program by calling the setNumberOfOMPThreads(n) function in the main function of the application, where n denotes the number of threads.
After adding the above modifications, the simulation will be executed in parallel, with only one additional line included to the main() function.
Alternatively, you can set the number of OMP threads using a command-line argument that is passed through helpers::readFromCommandLine(...) function:
In that case, the number of threads is set at execution-time via the command line, as follows:
Or you can use helpers::getMaximumNumberOfOMPThreads() the get the number of available OpenMP threads:
In this case, the number of threads is set at execution-time automatically:
For an example of an OpenMP-ready code, see /Drivers/MercurySimpleDemos/FreeCooling2DinWallsDemo.cpp.
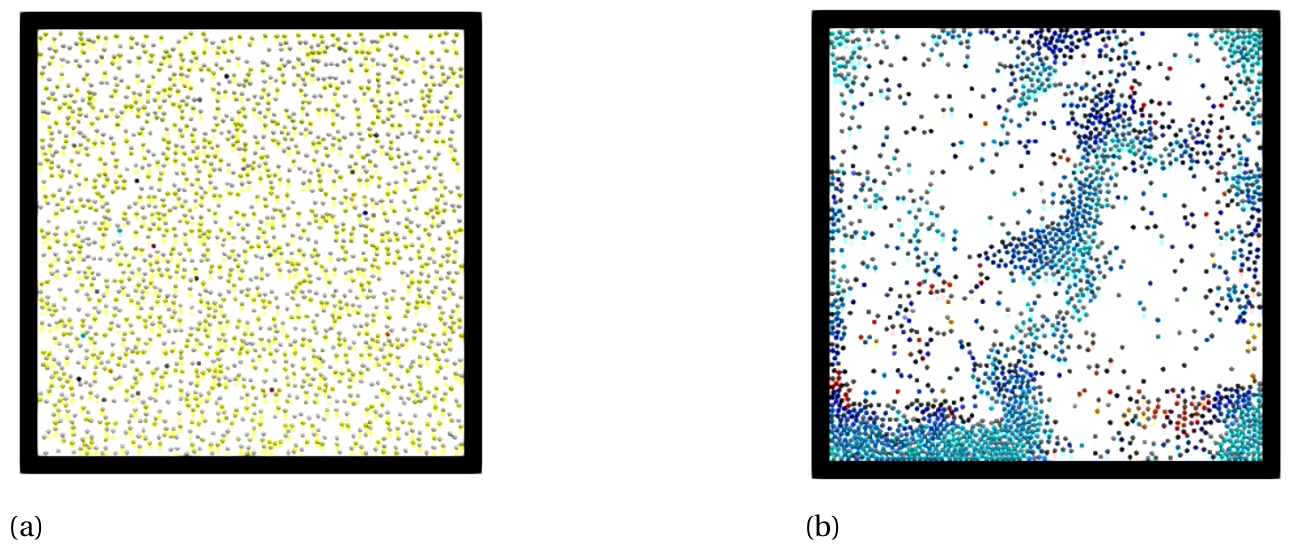
The table below shows performance results of the MercuryDPM-OpenMP framework:
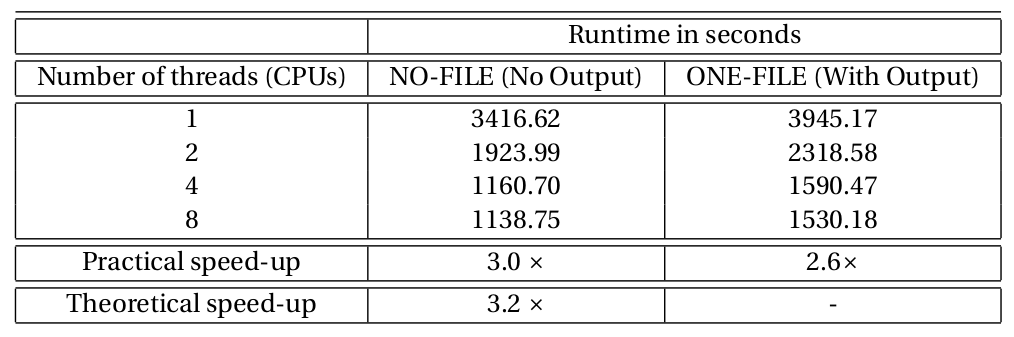
The performance was tested using 200,000-particle simulation of a cooling granular gas on a quad core processor, with a time step 5 x 10-5 and a save count = 100, simulated up to a maximum time = 0.1. The fully functional parallel program produced exactly the same (identical) output as the serial application. We see that the execution time decreases with the number of threads. The theoretical maximum speedup is based on Ahmdahl's law for 4 cores, assuming that 68% of the code can be parallelised.
On the following pages, you'll find more parallelisation demonstrations:
Parallel processing using MPI
Parallel processing for Input-Output, I/O files
Alternatively, go back to Overview of advanced tutorials